In a landmark 1988 interview with American journalist Bill Moyers, award-winning biochemist and science fiction author Isaac Asimov pointed out the fundamental flaw of conventional education:
Nowadays, what people call learning is forced on you and everyone is forced to learn the same thing on the same day at the same speed in class. And everyone is different. For some it goes too fast, for some too slow, for some in the wrong direction.
What Asimov went on to suggest is seen as a predictive vision of what the future of education could be:
Educational content tailored to each and every learner’s current level, interest, and learning pace.
But is that really the future?
Lingvist says no.
It’s now.
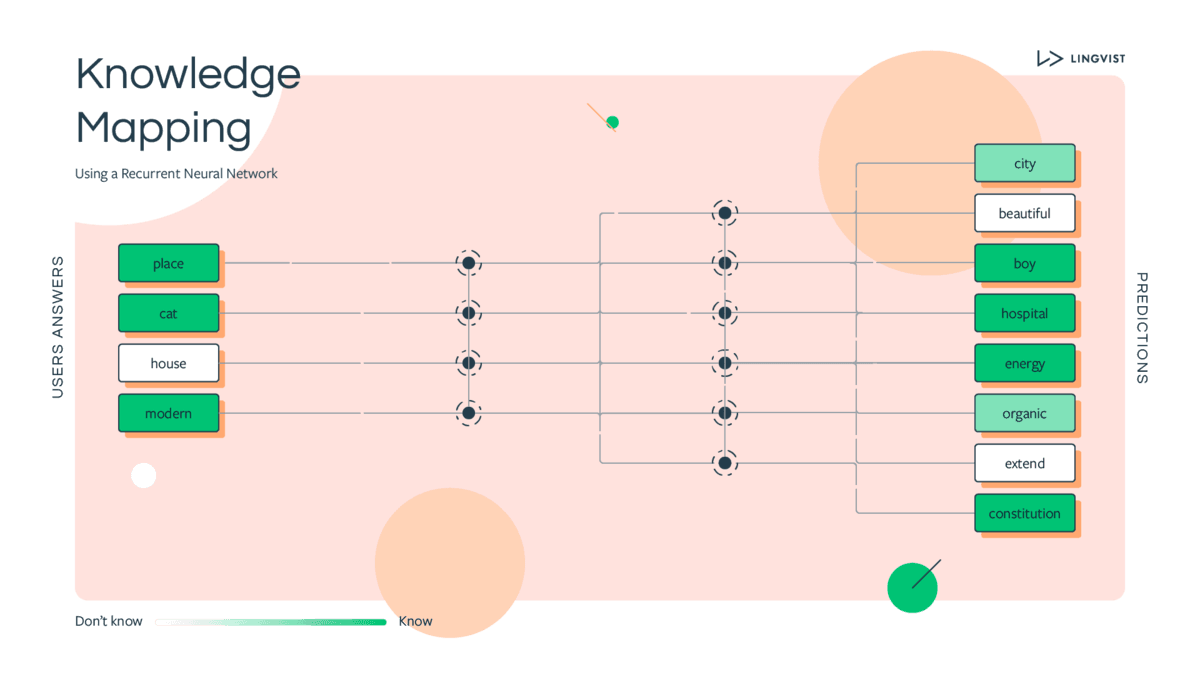
With Lingvist’s Knowledge Mapping Engine (KME), we change the way people learn by optimising the learner’s content to always reside in a sweet spot of learning. Knowledge Mapping drops you into this zone of the language learning process and works in real time to keep you there.
Why did Lingvist develop Knowledge Mapping technology, and why is it important for language learners?
At Lingvist, our pledge to learners is to improve their language skills as efficiently as possible. Our core premise is that we can achieve this by personalising the learning experience to focus on what each individual learner needs in order to make the most progress with any given learning session.
You know that feeling of really learning something — when what you’re studying is neither too easy nor too hard, and you’re applying your skills to their best measure? It’s called the Zone of Proximal Development (ZPD), and it’s exactly where learners want to be in order to get the optimal benefit out of the effort they put into learning. Get too much of what you already know or things you’re not yet ready for, and it’s a recipe for frustration.
A personalised learning experience like this, one that’s tailored to your strengths and weaknesses, can only happen if we have a good idea of what each learner already knows and how quickly they acquire new skills and facts.
To date, we’ve collected nearly half a billion learning events from our past and current learners. We’ve leveraged this to develop algorithms which predict and track each user’s knowledge as they learn and forget over time.
This is our Knowledge Mapping Engine.
The KME effectively does the job of a personal tutor who uses a wealth of teaching and language experience to gauge a student’s language skills and offer them the most appropriate activities to make progress towards their goals.
When and where in Lingvist do learners encounter the Knowledge Mapping Engine?
The Knowledge Mapping Engine starts its work the moment you start a new language course. We invite you to take a placement test, which estimates which words you already know in your target language. This gives the KME its first point of reference for your language knowledge, and it guides and builds your personal learning module to contain only material that you need to learn.
The KME then tracks your progress — both what you learn in a session and what you forget over time when you haven’t been learning. Lingvist uses this information to schedule each learning unit so that every session contains only what you need to review, and serves you new information when you’re most ready to absorb it.
How does Knowledge Mapping work?
The KME draws on the experience of all the people who have learned with Lingvist with the same source- and target-language pair.
This means that if you’re a native Chinese speaker learning English, we look at the experience of other Chinese speakers, rather than, say, French speakers, who would face different challenges when learning English.
The collective past learning history of all our learners is used to calibrate a first personalisation in the early stages of the KME, when we only have a little information about you. Currently, we use your guesses for the first 50 cards you complete (both correct and incorrect) to determine what you are likely to know and not know in the rest of the course.
This is how it works: After testing your ability to translate 50 words of varying difficulty, we predict your ability to answer a further 2000 words in the course correctly. Out of the words that the model forecasts you to know, the KME is up to 90% precise in its predictions.
When you start learning, every single answer you submit becomes an input for your personal model — what the KME has learned about how you learn. It then decides what the best next activity is. Say, for example, you’re struggling to remember how to translate a certain word; you would be asked to review that word more often. The KME also provides invaluable information to the linguistic specialists who engineer our course content by suggesting when a particular learning unit is less effective.
At every level of the Lingvist app, the KME is working to focus on and keep each and every learner in their own language learning sweet spot, that place in the Zone of Proximal Development that is always moving forward with you as you learn and master more material.
We at Lingvist believe that this very individual, real-time learning optimisation will not only change what people expect from a learning experience, but also how we fundamentally approach self-directed learning, making it not only faster and more effective, but more accessible too.
Read about how our data science helps us to change the way you learn.


